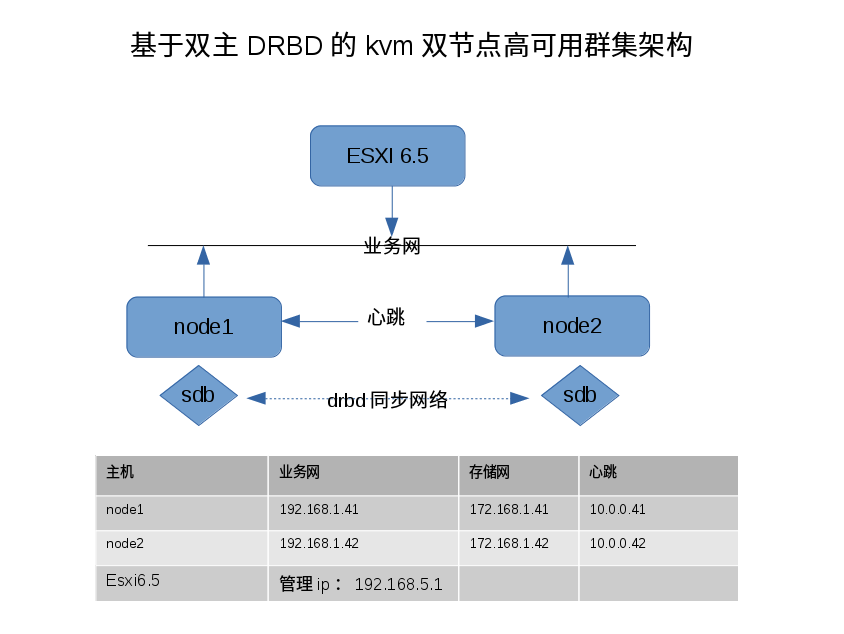
实验目的:构件基于本地存储,可平滑迁移虚拟机的kvm高可用平台 高可用架构:pacemaker+corosync 并由pcs进行管理 所需组件:DRBD,DLM,gfs2,clvm,pcs,pacemeker,corosync,libvirtd,qemu,qemu-img 系统环境:两台kvm节点都是最新的centos7.4,每台节点,挂载一块sdb 40G的磁盘
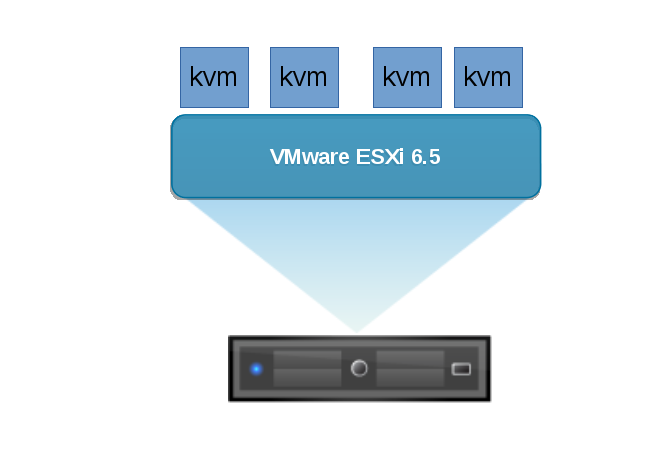
实验环境:kvm节点运行在ESXI6.5的宿主机上(如图)
软件安装(双节点操作)
#DRBD管理软件的安装(先添加key和elrepo源) rpm --import //www.elrepo.org/RPM-GPG-KEY-elrepo.org rpm -Uvh //www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm yum install kmod-drbd84 drbd84-utils -y #虚拟化软件安装 yum groups install -y "Virtualization Platform " yum groups install -y "Virtualization Hypervisor " yum groups install -y "Virtualization Tools " yum groups install -y "Virtualization Client " #群集及配套软件安装 yum install bash-completion ntpdate tigervnc-server -y yum install pacemaker corosync pcs psmisc policycoreutils-python fence-agents-all -y #gfs2和dlm还有clvm软件 yum install dlm lvm2-cluster gfs2-utils -y #升级标准的kvm组件为ev版本(可选) yum install centos-release-qemu-ev -y yum install qemu-kvm-ev -y #经测试,安装它后,创建虚拟机时会卡住 #或则运行下面一步到位 rpm --import //www.elrepo.org/RPM-GPG-KEY-elrepo.org && rpm -Uvh //www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm && yum install kmod-drbd84 drbd84-utils -y && yum groups install -y "Virtualization Platform " && yum groups install -y "Virtualization Hypervisor " && yum groups install -y "Virtualization Tools " && yum groups install -y "Virtualization Client " && yum install bash-completion ntpdate tigervnc-server centos-release-qemu-ev -y && yum install pacemaker corosync pcs psmisc policycoreutils-python fence-agents-all -y && yum install dlm lvm2-cluster gfs2-utils -y && reboot
准备阶段
1;主机名,hosts解析 10.0.0.31 node1 10.0.0.32 node2 2:ssh key互信 ssh-keygen -t rsa -P '' ssh-copy-id -i ~/.ssh/id_rsa.pub root@node1 #到自己免密码 ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2 #到node2免密码(双向) 3:每个node节点准备挂载一块40G的本地磁盘sdb 4:配置时区和时钟 cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime crontab -e */30 * * * * /usr/sbin/ntpdate time.windows.com &> /dev/null 5:在所有节点创建一个目录 mkdir /kvm-hosts 6:配置firewalld防火墙,将corosync,drbd的专用网段设置为全开放 firewall-cmd --zone=trusted --add-source=10.0.0.0/24 --permanent firewall-cmd --zone=trusted --add-source=172.168.1.0/24 --permanent firewall-cmd --reload 7:配置selinux yum install -y policycoreutils-python #安装这个软件包,才会有下面的 semanage permissive -a drbd_t 8:磁盘准备 #为本地的那块40G的磁盘创建lv(注意磁盘的大小要一致)(双节点都要做,建议将lv的名称都配置为一样的) fdisk /dev/sdb partprobe pvcreate /dev/sdb1 vgcreate vgdrbd0 /dev/sdb1 lvcreate -n lvdrbd0 -L 40G vgdrbd0
第一:配置DRBD(双节点操作)
#修改全局配置文件:
vi /etc/drbd.d/global_common.conf
usage-count yes; 改成no,这是使用计数,drbd团队收集互联网上有多少在使用drbd
#创建配置文件
vi /etc/drbd.d/r0.res
resource r0 {
protocol C;
meta-disk internal;
device /dev/drbd0;
disk /dev/vgdrbd0/lvdrbd0;
syncer {
verify-alg sha1;
}
on node1 {
address 172.168.1.41:7789;
}
on node2 {
address 172.168.1.42:7789;
}
#若是单主drbd可以不配置下面的参数,这里是双主需要配置
net {
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
disk {
fencing resource-and-stonith;
}
handlers {
fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
after-resync-target "/usr/lib/drbd/crm-unfence-peer.sh";
}
}
#初始化
drbdadm create-md r0
cat /proc/drbd #此时还看不到状态
modprobe drbd #加载drbd模块,
drbdadm up r0
cat /proc/drbd #此时便能看见状态
#同步(在其中一个节点上,将其置为主,并查看是否从指定网卡进行同步)
drbdadm primary r0 --force
ifstat #查看网卡流量
cat /proc/drbd #查看同步进度
#设drbd为开机启动
echo "drbdadm up r0 " >> /etc/rc.local
chmod +x /etc/rc.d/rc.local
第二:创建群集
systemctl start pcsd systemctl enable pcsd echo "7845" | passwd --stdin hacluster #前面三步是双节点操作,后面只需任一节点操作 pcs cluster auth node1 node2 -u hacluster -p 7845 pcs cluster setup --name kvm-ha-cluster node1 node2 #创建名为kvm-ha-cluster的群集,后面gfs2需要再次用到 pcs cluster start --all pcs cluster enable --all #开机自动启动所有群集节点(在生产环境中不要将群集设为开机自启动)
第三:配置STONITH(由于节点的承载平台是ESXI,所以这里用fence_vmware_soap)
#在双节点上查看是否安装了fence_vmware_soap pcs stonith list | grep fence_vmware_soap #在所有节点上,查看是否可以与esxi主机通信 [root@node1 ~] fence_vmware_soap -a 192.168.5.1 -z --ssl-insecure --action list --username="root" --password="tianyu@esxi" node1,564d59df-c34e-78e9-87d2-6551bdf96b14 node2,564d585f-f120-4be2-0ad4-0e1964d4b7b9 #尝试fence_vmware_soap 是否能控制esxi主机,对虚拟机进行操作(譬如:重启node2这台虚拟机) [root@node1 ~]# fence_vmware_soap -a 192.168.5.1 -z --ssl-insecure --action list -l root -p tianyu@esxi --plug="node2" --action=reboot Success: Rebooted 解释:-a指代ESXI的管理地址,-z 表示使用ssl连接443端口,-l 是esxi的管理用户名称,-p 是管理密码, --plug 是虚拟机名字,名称不唯一时可以为UUID, --action 是执行动作(reboot|off|on) #配置STONITH pcs cluster cib stonith_cfg pcs -f stonith_cfg stonith create MyVMwareFence fence_vmware_soap ipaddr=192.168.5.1 ipport=443 ssl_insecure=1 inet4_only=1 login="root" passwd="tianyu@esxi" action=reboot pcmk_host_map="node1:564d59df-c34e-78e9-87d2-6551bdf96b14;node2:564d585f-f120-4be2-0ad4-0e1964d4b7b9" pcmk_host_check=static-list pcmk_host_list="node1,node2" power_wait=3 op monitor interval=60s pcs -f stonith_cfg property set stonith-enabled=true pcs cluster cib-push stonith_cfg #更新 #注意 1:pcmk_host_map这里是在ESXI上显示的虚拟机的名字,不是kvm节点系统层面的主机名 2:pcmk_host_map后面格式是"虚拟机名字:UUID;虚拟机名字:UUID" #这是查看pcs关于fence_vmware_soap的stonith设置的写法 pcs stonith describe fence_vmware_soap #查看刚才配置好的stonith资源 [root@node1 ~]# pcs stonith show --full Resource: MyVMwareFence (class=stonith type=fence_vmware_soap) Attributes: action=reboot inet4_only=1 ipaddr=192.168.5.1 ipport=443 login=root passwd=tianyu@esxi pcmk_host_check=static-list pcmk_host_list=node1,node2 pcmk_host_map=node1:564df454-4553-2940-fac6-085387383a62;node2:564def17-cb33-c0fc-3e3f-1ad408818d62 power_wait=3 ssl_insecure=1 Operations: monitor interval=60s (MyVMwareFence-monitor-interval-60s) #查看刚才配置的stonith当出现脑裂时将会执行的动作 [root@node1 ~]# pcs property --all |grep stonith-action stonith-action: reboot 测试STONITH设置是否正确设置并生效 pcs status #先查看刚才创建的stonith资源MyVMwareFence是否已经在某个节点启动了(然后执行下面的验证) stonith_admin --reboot node2 #重启node2节点,验证成功
第四:配置DLM
pcs resource create dlm ocf:pacemaker:controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true #查看dlm是否启动了 pcs status systemctl status pacemaker
第五:为群集添加DRBD资源
#首先,要保证两个状态均为Secondary,数据状态都为UpToDate
[root@node1 ~]# cat /proc/drbd
version: 8.4.10-1 (api:1/proto:86-101)
GIT-hash: a4d5de01fffd7e4cde48a080e2c686f9e8cebf4c build by mockbuild@, 2017-09-15 14:23:22
0: cs:Connected ro:Secondary/Secondary ds:UpToDate/UpToDate C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
#若drbd状态现在是这样的Primary/Secondary
drbdadm down r0 #在Primary端做
drbdadm up r0 #在Primary端做,而后在查看cat /proc/drbd
#添加资源(这步操作会将两个节点的drbd状态变成Primary/Primary)
pcs cluster cib drbd_cfg
pcs -f drbd_cfg resource create VMdata ocf:linbit:drbd drbd_resource=r0 op monitor interval=60s
pcs -f drbd_cfg resource master VMdataclone VMdata master-max=2 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
pcs -f drbd_cfg resource show #检查是否正确
pcs cluster cib-push drbd_cfg #提交
#查看drbd两边的状态
cat /proc/drbd #结果是Primary/Primary ok
[root@node1 ~]# cat /proc/drbd
version: 8.4.10-1 (api:1/proto:86-101)
GIT-hash: a4d5de01fffd7e4cde48a080e2c686f9e8cebf4c build by mockbuild@, 2017-09-15 14:23:22
0: cs:Connected ro:Primary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:0 dw:0 dr:912 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
第六:创建CLVM,并配置约束

#将lvm工作模式设为群集模式(双节点操作) lvmconf --enable-cluster reboot #向群集添加CLVM资源 pcs resource create clvmd ocf:heartbeat:clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true #查看会发现clvm启动了 systemctl status pacemaker #配置约束 pcs constraint order start dlm-clone then clvmd-clone pcs constraint colocation add clvmd-clone with dlm-clone pcs constraint order promote VMdataclone then start clvmd-clone pcs constraint colocation add clvmd-clone with VMdataclone #验证查看约束 pcs constraint
第七:为群集创建LV
#根据场景,这里需要创建lvm的过滤属性,避免lvm会看到重复的数据(双节点操作) #其中一个节点 [root@node1 ~]# lvscan ACTIVE '/dev/vgdrbd0/lvdrbd0' [5.00 GiB] inherit ACTIVE '/dev/cl/swap' [2.00 GiB] inherit ACTIVE '/dev/cl/root' [28.99 GiB] inherit pvcreate /dev/drbd0 pvscan #发现报错 #(双节点操作) vi /etc/lvm/lvm.conf #找到filter,将其修改为如下 filter = [ "a|/dev/sd*|", "a|/dev/drbd*|", "r|.*|" ] #a 表示接受,r表示拒绝,这里sd*是本地磁盘,drbd*是创建的设备,根据自己实验环境修改,你的可能是vd* #再次查看 pvscan #没有错误了 #在所有节点刷新lvm vgscan -v #只需在其中一个节点创建lvm pvcreate /dev/drbd0 partprobe ; multipath -r vgcreate vgvm0 /dev/drbd0 lvcreate -n lvvm0 -l 100%FREE vgvm0 lvscan [root@node1 ~]# vgs VG #PV #LV #SN Attr VSize VFree cl 1 2 0 wz--n- <31.00g 4.00m vgdrbd0 1 1 0 wz--n- <40.00g <30.00g vgvm0 1 1 0 wz--nc <10.00g 0 #上面做完后,在另一个节点上刷新一下 partprobe ; multipath -r lvs
第八:配置gfs2(任意节点操作)
#格式化 lvscan mkfs.gfs2 -p lock_dlm -j 2 -t kvm-ha-cluster:kvm /dev/vgvm0/lvvm0 #向群集中添加gfs2文件系统 pcs resource create VMFS Filesystem device="/dev/vgvm0/lvvm0" directory="/kvm-hosts" fstype="gfs2" clone #配置约束 pcs constraint order clvmd-clone then VMFS-clone pcs constraint colocation add VMFS-clone with clvmd-clone #配置SELINUX(不然虚拟机无法访问存储文件)(所有节点都要做) semanage fcontext -a -t virt_image_t "/kvm-hosts(/.*)?" #如果没有semanage,可以如下安装 yum install policycoreutils-python restorecon -R -v /kvm-hosts
第九:准备测试用的虚拟机,配置防火墙,并进行在线迁移测试
#单点创建虚拟机 qemu-img create -f qcow2 /kvm-hosts/web01.qcow2 10G virt-install --name web01 --virt-type kvm --ram 1024 --cdrom=/kvm-hosts/CentOS-7-x86_64-Minimal-1708.iso --disk path=/kvm-hosts/web01.qcow2 --network network=default --graphics vnc,listen=0.0.0.0 --noautoconsole --os-type=linux --os-variant=rhel7 #配置第三方管理机能用virtual-manage连接并显示kvm-pt上的虚拟机(所有node节点都要) firewall-cmd --permanent --add-service=vnc-server #配置防火墙(所有kvm节点) firewall-cmd --permanent --add-port=16509/tcp #这是virsh -c qemu+tcp://node2/system 模式,这里不会用到,但还是放行 firewall-cmd --permanent --add-port=49152-49215/tcp #迁移端口 firewall-cmd --reload #创建前:要进行迁移测试(virt-manage和命令行) 结果:都ok,都能平滑迁移 virsh migrate web01 qemu+ssh://root@node2/system --live --unsafe --persistent --undefinesource
第十:为群集创建虚拟机资源,并配置相应约束
#在虚拟机运行节点上导出xml文件 virsh dumpxml web01 > /kvm-hosts/web01.xml virsh undefine web01 #创建虚拟机(虚拟机的磁盘文件和xml配置文件都要放在共享存储上)(虚拟机由群集软件来控制,不由本地的libvirt来控制) pcs resource create web01_res VirtualDomain \ hypervisor="qemu:///system" \ config="/kvm-hosts/web01.xml" \ migration_transport="ssh" \ meta allow-migrate="true" #配置约束(每配置一个虚拟机,就需要配置下面类似的约束) pcs constraint order start VMFS-clone then web01_res #先启动文件系统,在启动虚拟机资源 #当你对一个节点上的群集服务重启后,若是发现没有挂载gfs2文件系统到响应目录,解决办法有两个 1:停掉所有节点上的群集,做一次全部启动 2:在任意节点执行,下面的操作 pcs constraint colocation add web01_res with VMFS-clone #查找刚才创建约束的id,并立即删除 pcs constraint --full pcs constraint remove pcs constraint #查看约束,可以加 --full #配置完成后,虚拟机可以正常启动 最后:迁移测试 #pcs cluster standby node2 #平滑迁移ok #pcs resource move web01_res node2 #平滑迁移ok #pcs cluster stop #平滑迁移ok #init 6 #平滑迁移no
原文来自:
本文地址://lrxjmw.cn/drbd-kvm.html编辑:xiangping wu,审核员:逄增宝
Linux命令大全:
Linux系统大全: