| 导读 | 实战场景:Python 如何实现采集二手房列表信息并存储文件 |
列表页数据采集
'''
Description: 代码供参考学习使用
'''
from __future__ import annotations
import os
import platform
import pandas as pd
from bs4 import BeautifulSoup
from tqdm import tqdm # 进度条库
from base_spider import BaseSpider
from base_url_item import UrlItem
class Tao365Spider(BaseSpider):
# 采集365淘房二手房信息
target_url = "//nj.sell.house365.com/district/p1.html" # 采集目标链接
list_data_file = 'tao365_list.csv' # 采集数据保存的文件
url_items: list[UrlItem] = [] # 采集链接数组
PAGE_START = 1 # 采集开始页码
PAGE_STEP = 5 # 采集步长
def __init__(self):
# 初始化日志
self.init_log()
# 默认采集的上一页为第 1 页
start_page = self.PAGE_START
list_file_path = self.fileManger.get_data_file_path(self.list_data_file)
if os.path.isfile(list_file_path):
# 读取列表文件, 确定上一次采集的第几页, 以支持连续采集
self.logger.info("数据文件存在")
self.data_file_exist = True
# 计算从第几页开始采集
list_df = pd.read_csv(list_file_path, usecols=['第几页'], encoding=self.encoding)
max_page = pd.DataFrame(list_df[2:]).max()
start_page = int(max_page) + 1
print("采集页面范围: 第[%s]页至第[%s]页" % (start_page, start_page + self.PAGE_STEP - 1))
for page in range(start_page, start_page + self.PAGE_STEP):
# 初始化采集链接
url = self.target_url.replace("p1", "p" + str(page))
# 构造采集对象
url_item = UrlItem(url=url, page=page)
self.url_items.append(url_item)
def crawl_data(self):
for url_item in tqdm(self.url_items):
# 采集数据
url = url_item.url
self.logger.debug("当前采集页面信息: %s", url)
# 发送请求, 获取数据
page_content = self.get_content_from_url(url)
# 解析数据
page_data = self.parse_page(page_content, url_item)
self.logger.debug("采集数据量: %s", len(page_data))
# 保存数据到文件
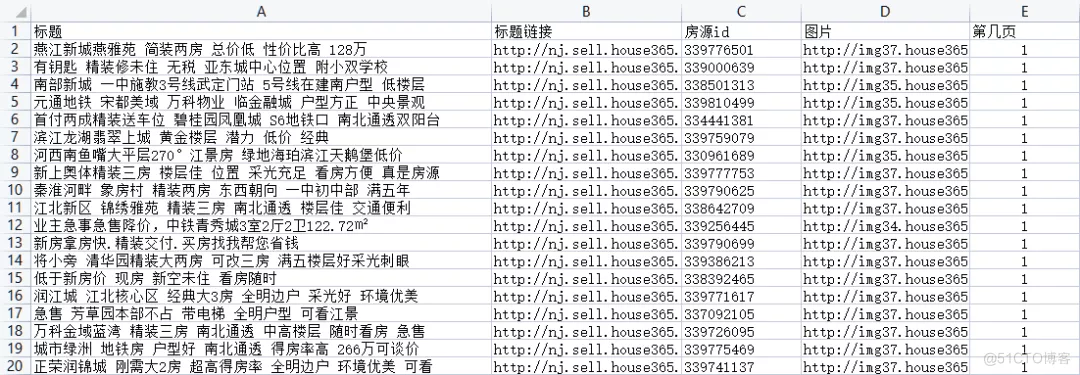
cols = ['标题', '标题链接', '房源id', '图片', '第几页']
self.save_to_file(page_data, cols)
# 防止反爬, 随机休眠一段时间
self.sleep_random()
def parse_page(self, content, url_item: UrlItem):
# 利用BeautifulSoup标准库,解析页面信息
soup = BeautifulSoup(content, 'lxml')
# 初始化数组
datalist = []
for element in soup.find_all("div", attrs={'class': 'listItem'}):
# 解析单条信息
# 判断是否为有效数据
if element.img.has_attr("data-original"):
# 依次解析, 标题, 标题链接, 房源id, 图片
title = element.find("a", class_='listItem__title').text.strip()
title_link = element.find("a", class_='listItem__title')['href']
house_id = element.find("a", class_='listItem__title')['house-id']
image = element.img["data-original"]
datalist.append([title, title_link, house_id, image, url_item.page])
return datalist
def run(self):
self.logger.debug("采集开始")
self.crawl_data()
self.logger.debug("采集结束")
if __name__ == '__main__':
print("采集365淘房二手房信息")
spider = Tao365Spider()
spider.run()
print("python 版本", platform.python_version())
存储采集数据到文件
def save_to_file(self, data, cols):
# 保存到文件
file_path = self.fileManger.get_data_file_path(self.list_data_file)
# 初始化数据
frame = pd.DataFrame(data)
if not self.data_file_exist:
# 第一次写入带上列表头,原文件清空
frame.columns = cols
frame.to_csv(file_path, encoding=self.encoding, index=None)
self.data_file_exist = True # 写入后更新数据文件状态
else:
# 后续不写如列表头,追加写入
frame.to_csv(file_path, mode="a", encoding=self.encoding, index=None, header=0)
self.logger.debug("文件保存完成")
运行结果
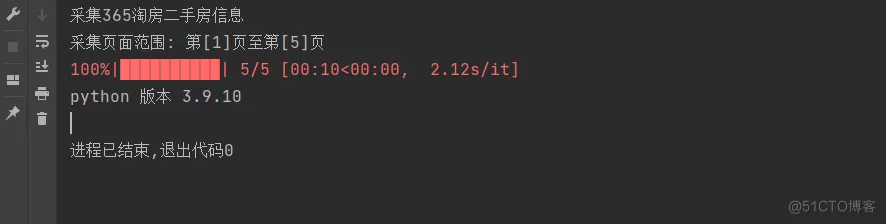
结果文件
原文来自:
本文地址://lrxjmw.cn/python-collect-data.html编辑:薛鹏旭,审核员:逄增宝
Linux大全:
Linux系统大全: